
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- APP
- Toast Message
- Django
- 빅데이터
- BigData
- AI
- 디자인패턴
- ios toast message
- python
- toast
- Artificial Intelligence
- 템플릿
- 시각화
- swift
- 딥러닝
- 파이썬
- 장고
- model
- 모델
- 인공지능
- swift toast message
- Android
- Pycharm
- 머신러닝
- view
- 앱
- 기계학습
- IOS
- Deep learning
- Machine Learning
- Today
- Total
이끼의 생각
8. [머신러닝] 강화학습과 이용, 탐험, 마르코프 결정 프로세스 본문
강화 학습(Reinforcement Learning)
위의 두 문제의 분류는 지도의 여부에 따른 것이었는데, 강화학습은 조금 다릅니다. 지도 학습과 비지도 학습이 학습 데이터가 주어진 상태에서 환경에 변화가 없는 정적인 환경에서 학습을 진행했다면, 강화 학습은 어떤 환경 안에서 정의된 주체(agent)가 현재의 상태(state)를 관찰하여 선택할 수 있는 행동(action)들 중에서 가장 최대의 보상(reward)을 가져다주는지 행동이 무엇인지를 학습하는 것입니다. 즉, 현재의 상태(State)에서 어떤 행동(Action)을 취하는 것이 최적인지를 학습하는 것입니다.
강화 학습은 주체(agent)가 환경으로부터 보상을 받음으로써 학습하기 때문에 지도 학습과 유사해 보이지만, 사람으로부터 학습을 받는 것이 아니라 변화되는 환경으로부터 보상을 받아 학습한다는 점에서 차이를 보입니다.
행동을 취할 때마다 외부 환경에서 보상(Reward)이 주어지는데, 이러한 보상을 최대화 하는 방향으로 학습이 진행됩니다. 그리고 이러한 보상은 행동을 취한 즉시 주어지지 않을 수도 있습니다(지연된 보상). 그렇기 때문에 문제의 난이도가 앞의 두개에 비해 대폭 상승하며, 시스템을 제대로 보상하는 것과 관련된 신뢰 할당 문제 라는 난제가 여전히 연구원들을 괴롭히고 있습니다 .
대표적으로 게임 인공지능을 만드는 것을 생각해볼 수 있습니다. 체스에서 현재 나와 적의 말의 배치가 State가 되고 여기서 어떤 말을 어떻게 움직일지가 Action이 됩니다. 상대 말을 잡게 되면 보상이 주어지는데, 상대 말이 멀리 떨어져 이동할 때 까지의 시간이 필요할 수 있으므로, 상대 말을 잡는 보상은 당장 주어지지 않는 경우도 생길 수 있습니다.
심지어 그 말을 잡은 것이 전술적으로는 이익이지만 판세로는 불이익이라 다 끝났을 때 게임을 질 수도 있습니다. (지연된 보상). 따라서 강화학습에서는 당장의 보상값이 조금은 적더라도, 나중에 얻을 값을 포함한 보상값의 총 합이 최대화되도록 Action을 선택해야 하며, 게다가 행동하는 플레이어는 어떤 행동을 해야 저 보상값의 합이 최대화되는지 모르기 때문에, 미래를 고려하면서 가장 좋은 선택이 뭔지 Action을 여러 방식으로 수행하며 고민해야 합니다.
좋은 선택이 뭔지 Action을 찾는 것을 탐색, 지금까지 나온 지식을 기반으로 가장 좋은 Action을 찾아 그것을 수행하는 것을 활용한다고 하여, 강화학습을 푸는 알고리즘은 이 둘 사이의 균형을 어떻게 잡아야 할지에 초점을 맞추어야 합니다. 앞서 애기한 방법들과는 다르게 실시간으로 학습을 진행하는 게 일반적이다.
이러한 강화 학습은 사람이 지식을 습득하는 방식 중 하나인 시행착오를 겪으며 학습하는 것과 매우 흡사하여 인공지능을 가장 잘 대표하는 모델로 알려져 있습니다.
강화 학습의 동작 순서
강화 학습은 일반적으로 다음과 같은 순서대로 학습을 진행하게 됩니다.
1. 정의된 주체(agent)가 주어진 환경(environment)의 현재 상태(state)를 관찰(observation)하여, 이를 기반으로 행동(action)을 취합니다.
2. 이때 환경의 상태가 변화하면서 정의된 주체는 보상(reward)을 받게 됩니다.
3. 이 보상을 기반으로 정의된 주체는 더 많은 보상을 얻을 수 있는 방향(best action)으로 행동을 학습하게 됩니다.
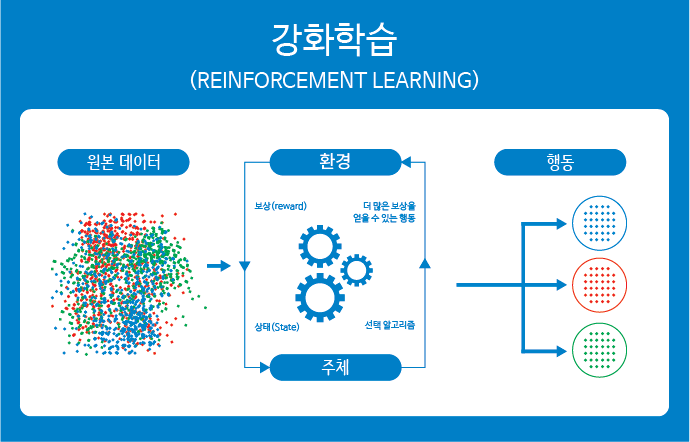
강화 학습에서의 ‘관찰–행동–보상’에 이르는 일련의 과정을 경험(experience)이라고 부를 수 있습니다.
이용(exploitation)과 탐험(exploration) 사이의 균형
경험을 통해 학습하는 강화 학습에서 최단 시간에 주어진 환경의 모든 상태를 관찰하고, 이를 기반으로 보상을 최대화할 수 있는 행동을 수행하기 위해서는 이용(exploitation)과 탐험(exploration) 사이의 균형을 적절히 맞춰야 합니다.
이용(exploitation)이란 현재까지의 경험 중 현 상태에서 가장 최대의 보상을 얻을 수 있는 행동을 수행하는 것을 의미하고, 이러한 다양한 경험을 쌓기 위해서는 새로운 시도가 필요한데 이러한 새로운 시도를 탐험(exploration)이라고 합니다.
탐험을 통해 얻게 되는 경험이 언제나 최상의 결과일 수는 없기에 이 부분에서 낭비가 발생하게 됩니다. 즉, 풍부한 경험이 있어야만 더 좋은 선택을 할 수 있게 되지만, 경험을 풍부하게 만들기 위해서는 새로운 시도를 해야 하고 이러한 새로운 시도는 언제나 위험 부담을 가지게 됩니다.
예를 들어, 빵집에 가서 지금까지 자신이 먹어본 빵 중 가장 맛있는 빵을 고르는 것이 이용(exploitation)이 되며, 한 번도 먹어보지 못한 다른 빵을 고르는 것이 탐험(exploration)이 됩니다. 만약 새로 고른 빵이 가장 맛있다고 느껴지면 다음 번 선택에서 이용될 수 있으나, 만약 맛이 없었다면 한 번의 기회를 낭비하게 된 것입니다.
따라서 이용과 탐험 사이의 적절한 균형을 맞추는 것이 강화 학습의 핵심이 되는 것입니다.
마르코프 결정 프로세스(Markov Decision Process, MDP)
강화 학습에서 보상을 최대화할 수 있는 방향으로 행동을 취할 수 있도록 이용과 탐험 사이의 적절한 균형을 맞추는데 사용되는 의사결정 프로세스가 바로 마르코프 결정 프로세스(Markov Decision Process, MDP)입니다.
MDP에서 행위의 주체(agent)는 어떤 상태(state)를 만나면 행동(action)을 취하게 되며, 각 상태에 맞게 취할 수 있는 행동을 연결해 주는 함수를 정책(policy)이라고 합니다. 따라서 MDP는 행동을 중심으로 가치 평가가 이루어지며, MDP의 가장 큰 목적은 가장 좋은 의사결정 정책(policy) 즉 행동에 따른 가치(value)의 합이 가장 큰 의사결정 정책을 찾아내는 것입니다.
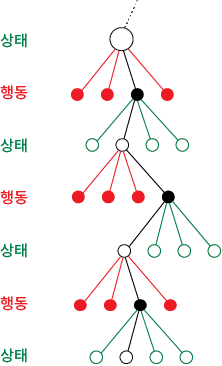
이러한 MDP는 여러 방식을 통해 풀 수 있으며, 일반적으로 동적 계획법(dynamic programming)인 가치 반복법(Value Iteration, VI)이나 정책 반복법(Policy Iteration, PI), 선형 계획법(linear programming)인 Q러닝(Q-Learning) 등을 사용하여 그 해를 구하게 됩니다.
강화 학습의 활용
강화 학습은 프로세스 제어, 네트워크 관리, 로봇공학 등 현재 다양한 분야에서 활용되고 있습니다.
우리에게 익숙한 인공지능인 알파고도 바둑의 기본 규칙과 자체 경기를 통해 습득한 3,000만 개의 기보를 학습한 후 스스로 대국하며 훈련하는 강화 학습 알고리즘을 사용하여 개발되었습니다.
또한, 자율 주행 자동차와 드론 분야 등에서도 강화 학습을 활용한 다양한 연구 및 시도가 활발히 진행되고 있습니다.
** 출처 및 참고 **
'인공지능 이론 > 쉽게 읽는 인공지능과 머신러닝, 딥러닝 이론' 카테고리의 다른 글
| 10. 딥러닝이란? (0) | 2019.05.21 |
|---|---|
| 9. [머신러닝] 학습을 위한 다양한 알고리즘 (0) | 2019.05.21 |
| 7. [머신러닝] 비지도학습과 군집화, 분포, 분류, 타당성 평가 (0) | 2019.05.21 |
| 6. [머신러닝] 지도학습과 분류, 회귀, 예측 (0) | 2019.05.21 |
| 5. 머신러닝이란? (0) | 2019.05.21 |