
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 템플릿
- Pycharm
- 인공지능
- Django
- swift
- 딥러닝
- Deep learning
- 빅데이터
- IOS
- toast
- Android
- swift toast message
- BigData
- python
- model
- Machine Learning
- AI
- 기계학습
- 파이썬
- 앱
- 모델
- view
- ios toast message
- Toast Message
- APP
- Artificial Intelligence
- 디자인패턴
- 장고
- 머신러닝
- 시각화
- Today
- Total
이끼의 생각
6. [머신러닝] 지도학습과 분류, 회귀, 예측 본문
머신러닝의 분류
머신러닝은 학습하려는 문제의 유형에 따라 크게 다음과 같은 세 가지로 분류할 수 있습니다.
1. 지도 학습(Supervised Learning)
2. 비지도 학습(Unsupervised Learning)
3. 강화 학습(Reinforcement Learning)
지도 학습(Supervised Learning)
지도 학습(Supervised Learning)이란 간단히 말해 선생님이 문제를 내고 그 다음 바로 정답까지 같이 알려주는 방식의 학습 방법입니다.
즉, 여러 문제와 답을 같이 학습함으로써 미지의 문제에 대한 올바른 답을 예측하고자 하는 방법입니다.
따라서 지도 학습을 위한 데이터에는 문제와 함께 그 정답까지 함께 알고 있는 데이터가 선택됩니다.
예를 들어, “장미꽃이 찍혀 있는 이미지 데이터”에 레이블로 “해당 장미꽃의 품종을 나타내는 텍스트“를 함께 입력하여 학습기를 지도 학습시키면, 다른 장미꽃이 찍힌 새로운 이미지를 받았을 때 해당 장미꽃의 품종이 무엇인지를 예측할 수 있게 되는 것입니다.
학습기(learner)에 데이터와 함께 입력하는 정답을 레이블(label)이라고 부릅니다. 사람이 교사로써 각각의 입력(x)에 대해 레이블(y)을 달아놓은 데이터를 컴퓨터에 주면 컴퓨터가 그것을 학습하는 것입니다. 사람이 직접 개입하므로 정확도가 높은 데이터를 사용할 수 있다는 장점이 있습니다. 대신에 사람이 직접 레이블을 달아야 하므로 인건비 문제가 있고, 따라서 구할 수 있는 데이터양도 적다는 문제가 있습니다.
지도 학습 모델
머신러닝에서 지도 학습을 위한 모델은 크게 분류(classification) 모델과 예측(prediction) 모델로 구분됩니다.
분류 모델은 사용하는 알고리즘에 따라 또다시 KNN(K Nearest Neighbor), 서포트 벡터 머신(Support Vector Machine, SVM), 의사결정 트리(decision trees) 등의 모델로 구분되며, 예측 모델로는 회귀(regression) 모델이 대표적으로 사용되고 있습니다.
분류 모델과 예측 모델 모두 지도 학습 모델이므로, 데이터와 레이블을 함께 학습시킨다는 공통점을 가집니다.
하지만 분류 모델은 학습 데이터의 레이블 중 하나가 결괏값이 되고, 예측 모델은 학습 데이터에서 도출된 함수식에서 계산된 임의의 값이 결괏값이 되는 점이 서로 다릅니다.
분류(classification) 모델
분류 모델은 레이블이 달린 학습 데이터로 학습한 후에 새로 입력된 데이터가 학습했던 어느 그룹에 속하는 지를 찾아내는 방법입니다. 분류 모델의 결괏값은 언제나 학습했던 데이터의 레이블 중 하나가 됩니다.
레이블 y가 이산적(Discrete)인 경우 즉, y가 가질 수 있는 값이 [0,1,2 ..]와 같이 유한한 경우 분류, 혹은 인식 문제라고 부릅니다. 일상에서 가장 접하기 쉬우며, 연구가 많이 되어있고, 기업들이 가장 관심을 가지는 문제 중 하나입니다. 이런 문제들을 해결하기 위한 대표적인 기법들로는 로지스틱 회귀법, KNN, 서포트 벡터 머신 (SVM), 의사 결정 트리 등이 있습니다.
즉, 다음과 같은 이미지를 통해 학습한 결과 새로운 이미지에 해당하는 숫자가 0인지 1인지를 파악하는 것입니다.
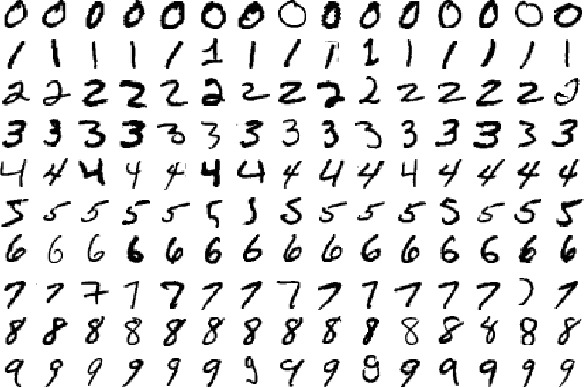
예시1) ‘가’, ‘나’, ‘다’라는 레이블이 달린 데이터를 분류 모델로 지도 학습한 후, 새로운 데이터를 분석한 결과는 반드시 ‘가’, ‘나’, ‘다’ 중의 하나가 되는 것입니다.
예시2) 주차게이트에서 번호판 인식
요새 주차장들은 티켓을 뽑지 않고, 차량 번호판을 찍어서 글자를 인식하는데 정확도를 높인다. 번호판은 정형화 되어있으므로 전통적인 컴퓨터 비전으로도 처리는 가능하나, 오염 등에 대해 정확도를 높이자면 기계학습을 하면 더 좋다. 이미지 픽셀 값들에 따라 숫자 글자를 분류한다.
예시3) 페이스북이나 구글 포토의 얼굴 인식: 역시 컴퓨터 비전을 이용하되 기계학습을 결합. 페이스북에 사진을 올리면 친구 얼굴 위에 이름이 자동으로 달리고는 하는데, 이것 역시 기계학습을 이용한 것. x가 이미지 픽셀, y가 사람 이름인 경우.
예시4) 음성 인식: 음성 wav 파일에 대해서 해당 wav 부분이 어떤 음절인지를 인식하는 것. 애플 시리, 구글 보이스 등에서 사용된다(질문에 대해서 답해주는 부분 말고, 인식 부분만). x가 음성 파형, y가 음절.
이러한 유형의 문제는 일상에서 흔히 접할 수 있는 문제이며, 따라서 이에 관한 연구가 많이 진행되어 있습니다. 또한 기업에서도 많은 관심을 가지고 있는 문제 중 하나입니다.
회귀 분석(regression analysis)
레이블 y가 실수인 경우 회귀문제라고 부릅니다. 보통 엑셀에서 그래프 그릴 때 많이 접하는 것인데 특징량을 바탕으로 구분선을 찾아내는 것을 머신러닝이라고 정의하였는데, 이러한 구분선을 찾아내는 방법 중 가장 널리 사용되는 방식이 바로 회귀 분석(regression analysis)입니다.
데이터들을 쭉 뿌려놓고 이것을 가장 잘 설명하는 직선 하나 혹은 이차함수 곡선 하나를 그리고 싶을 때 회귀기능을 사용합니다. 잘 생각해보면 데이터는 입력(x)와 실수 레이블(y)의 짝으로 이루어져있고, 새로운 임의의 입력(x)에 대해 y를 맞추는 것이 바로 직선 혹은 곡선이므로 기계학습 문제가 맞게 되죠.
통계학의 회귀분석 기법 중 선형회귀 기법이 이에 해당하는 대표적인 예입니다. 통계학에서 주로 사용되는 회귀 분석(regression analysis)이란 여러 자료들 간의 관계성을 수학적으로 추정하고 분석하는 데이터 분석 방법 중 하나입니다. 이러한 회귀 분석은 주로 시간에 따라 변화하는 데이터나 가설, 인과 관계 등의 통계적 예측에 사용됩니다.
회귀 분석에서 종속변수란 우리가 알고 싶어 하는 결괏값을 가리키며, 독립변수란 이러한 결괏값에 영향을 주는 입력값을 가리킵니다.
그리고 하나의 종속변수와 하나의 독립변수 사이의 관계를 분석할 경우를 단순 회귀 분석(simple regression analysis)이라고 구분하여 부릅니다.
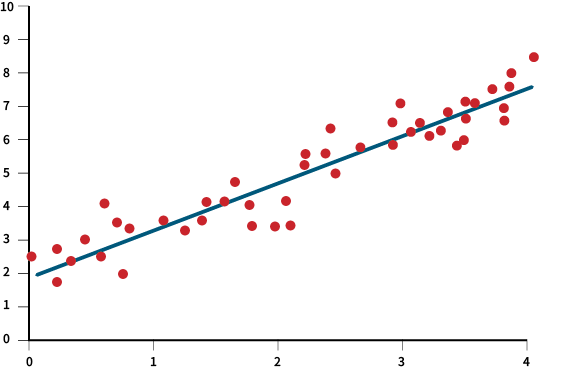
단순 회귀 분석에서 하나의 방정식은 독립변수와 종속변수의 상관관계를 보여주는 분포구성을 통해 중심을 지나가는 하나의 선으로 표시할 수 있으며, 바로 이것을 이용하여 머신러닝에서는 특징량에 따른 구분선을 찾아낼 수 있게 되는 것입니다.
예측 모델(predictive model)
예측 모델도 분류 모델과 마찬가지로 지도 학습 모델이므로 레이블이 달린 학습 데이터로 학습하게 됩니다.
하지만 예측 모델은 분류 모델과는 달리 레이블이 달린 학습 데이터를 가지고 특징(feature)과 레이블(label) 사이의 상관관계를 함수식으로 표현하게 됩니다.
따라서 ‘가’, ‘나’, ‘다’라는 레이블이 달린 데이터를 예측 모델로 지도 학습하였다고 하더라도 분류 모델처럼 결괏값이 반드시 ‘가’, ‘나’, ‘다’ 중 하나가 되는 것이 아니라 해당 범위 내의 어떠한 값도 나올 수 있는 것입니다. 이처럼 어떠한 값이 결과로 나올지 예상할 수 없으므로, 이를 예측 모델이라고 부릅니다.
이러한 예측 모델은 주가나 환율 분석 등과 같이 연속적인 범위 내의 값에서 그 결괏값을 예측하는 문제에 일반적으로 많이 활용됩니다.
** 출처 및 참고 **
'인공지능 이론 > 쉽게 읽는 인공지능과 머신러닝, 딥러닝 이론' 카테고리의 다른 글
| 8. [머신러닝] 강화학습과 이용, 탐험, 마르코프 결정 프로세스 (0) | 2019.05.21 |
|---|---|
| 7. [머신러닝] 비지도학습과 군집화, 분포, 분류, 타당성 평가 (0) | 2019.05.21 |
| 5. 머신러닝이란? (0) | 2019.05.21 |
| 4. 인공지능과 머신러닝, 딥러닝 (0) | 2019.05.21 |
| 3. 인공지능 모델, 튜링 테스트와 알파고 (0) | 2019.05.21 |
