구글 인셉션 Google Inception(GoogLeNet) 알아보기
이번에 알아볼 내용은 하나의 논문을 공부하는 것은 아니지만 유명한 뉴럴네트워크인 구글의 GoogLeNet에 대해 알아보겠습니다.
직접 딥러닝/머신러닝 아키텍처와 알고리즘들을 구현하지 않고 편리하게 텐서플로우를 이용하여 딥러닝 기능을 응용 소프트웨어에 적용할 수 있지만, 원리를 조금 더 알아보고 논문, 구현을 한 사람들의 의도와 고뇌를 알아보고자 정리를 하게 되었습니다.

GoogLeNet
GoogLeNet은 2014년 ImageNet에서 개최한 ILSVRC14 (ImageNet Large-Scale Visual Recognition Challenge 2014)에서 VGGNET을 간신히(?) 제치고 1등을 하였습니다.
대회 우승 직후 Going Deeper With Convolutions 라는 논문을 발표하며 Inception이라는 이름의 GoogLeNet에 대한 연구를 다루었죠.
Going Deeper With Convolutions, Christian Szegedy, Google Inc, 2014
ILSVRC14 당시 GoogLeNet 이라는 팀명으로 출전하였고, GoogLeNet이 Inception의 여러 버전 중 하나라고 밝혔는데 Inception-v1이 GoogLeNet입니다.(혼란 없으시길..)
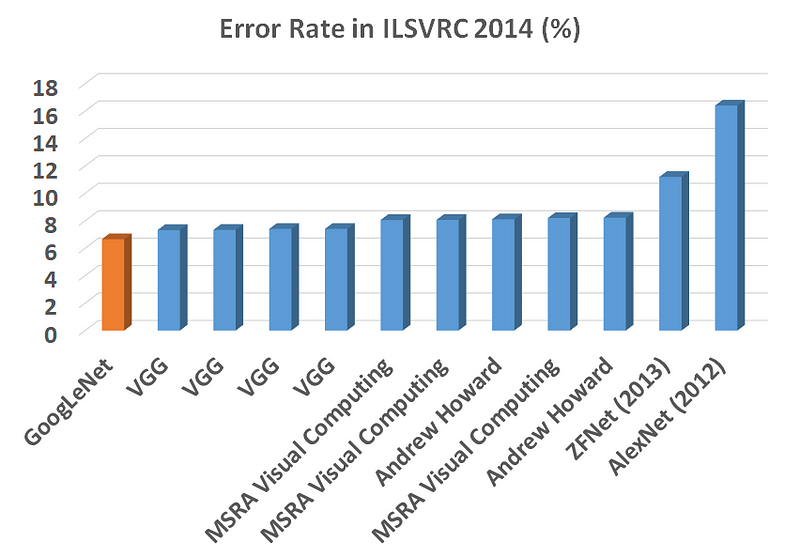
GoogLeNet과 VGGNet 모두 7% 라는 엄청나게 적은 에러율을 보여주었는데, 수치상 사람의 인식 에러율이 5%라고 하면 엄청난 수치라는걸 알 수 있습니다.
2016년 알파고가 등장하기 전, ILSVRC12에서 토론토대학의 알렉스 크리제브스키교수가 보여준 AlexNet이 등장한지 불과 2년만에 인간의 인식수준에 도달한거죠.
Deep Problem
인셉션에 대해 애기하기전 딥러닝의 대해 알아보겠습니다.
딥러닝을 이용하여 ImageNet와 같은 큰 대회나 서비스 가능한 수준의 인식률을 갖추기 위해서는 대용량의 데이터를 학습을 해야됩니다. 딥뉴럴네트워크의 아키텍쳐에서 레이어가 넓고(뉴런이 많고), 깊으면(레이어가 많으면) 인식률이 좋아집니다. 하지만, 딥러닝의 고질병인 Overfitting, Vanshing Gradient Problem 를 비롯한 총 학습시간, 연산속도 등의 문제점을 안게 됩니다.
여기서 이미지, 다차원 포멧의 데이터를 학습하는데 사용하는 대표적인 알고리즘인 Convolution Neural Network라면 이러한 문제점이 아주 잘 나타납니다. Deep한 Architecture 갖는 Fully Connectied 뿐만 아닌 이미지를 처리하는 Convolution 에서도 이런 특징이 나타납니다.
CNN에서 이미지 데이터가 Convolution 연산을 먼저 거치게 될때 Channel(C)이 커지고, 이미지의 Height(H), Width(W) 가 줄어 듭니다. 이 첫번째 연산은 콘볼루션 연산으로 원본 이미지와 함께 연산될 Filter(or Kernel)가 필요한데 이 Filter의 크기가 하이퍼파라미터가 되며 Filter크기에 따라 Computational Resource가 크게 달라집니다.
또한, Convolution 연산을 위해 Stride와 Padding 값 역시 Hyper Param 이므로 Filter, Stride, Padding 값에 비례하여 Convolution Layer가 Deep하게 되면 엄청난 연산이 됩니다.
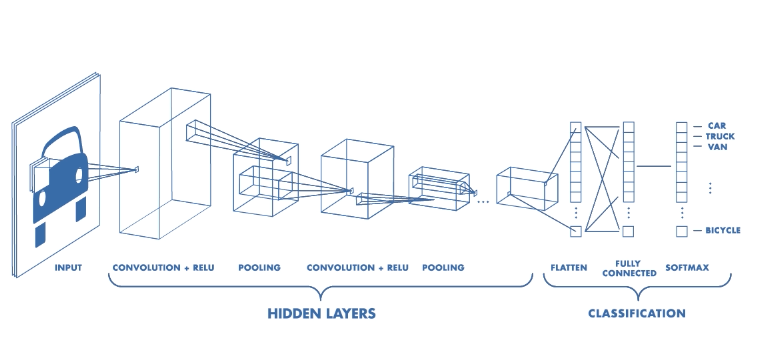
CNN에서 Convolution Layer에서 연산의 Output 값들을 거의 대부분 Pooling을 거치며 Affine 역시 자주 사용됩니다.
Pooling에서도 Filter Size와 Stride 값 등 Hyper Param으로, 역시 부담스러운 Computational Resource를 크게 사용할 겁니다.
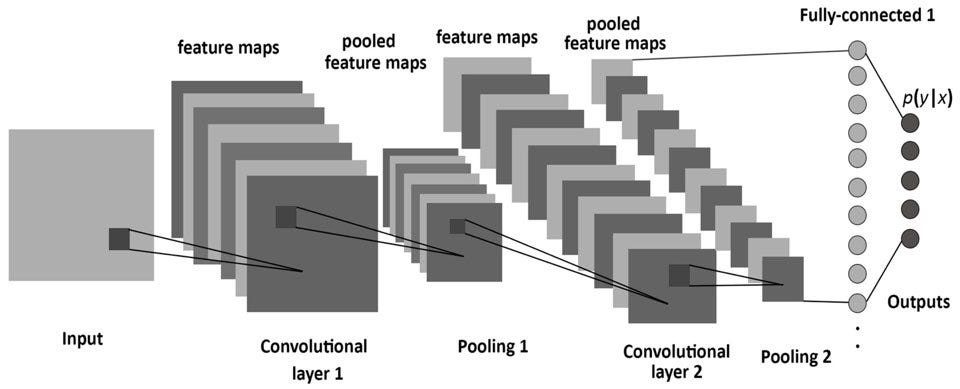
이렇게 Weight, Bias, Momentum(Error Function), Neural 개수, Layer 깊이 등 Hyper Parameter들과 방금 집어본 CNN의 Hyper Parameter 들을 설정하여 우리가 사용할 Deep Neural Network의 Architecture를 구성해야됩니다.
실제로 DNN이 사용되는 상황이 여러분들의 프로젝트의 요구사항에 기반하여 Optimal 한 초기값을 설정해주고 학습을 진행하면서 Hyper Params의 Optimization 기법들 그리고 Drop Out L1, L2 Norm 등의 정규화 기법들을 사용해야 되는데 엔지니어의 가장 큰 고민거리가 됩니다.
Solution But Another Problem
GoogLeNet에 적용된 해결방안 중 하나가 Sparse Connectivity 입니다. CNN은 Convolution, Pooling, Fully Connected 계층들이 서로 Dense하게 연결 되어있습니다.(정교하고 뺵뺵하게!!)
Network를 Sparse하게!!
이렇게 높은 관련성(Correlation)을 가진 노드끼리만 연결하는 방법인데, 연결을 Sparse 하게 바꾸어서 연산량, 파라미터를
Computational Resource를 적게 사용하는 방법입니다. 이렇게하면 Overfitting 또한 개선 되는다 Fully Connected, 일반적인 DNN에서 Dropout과 유사한 기법입니다.
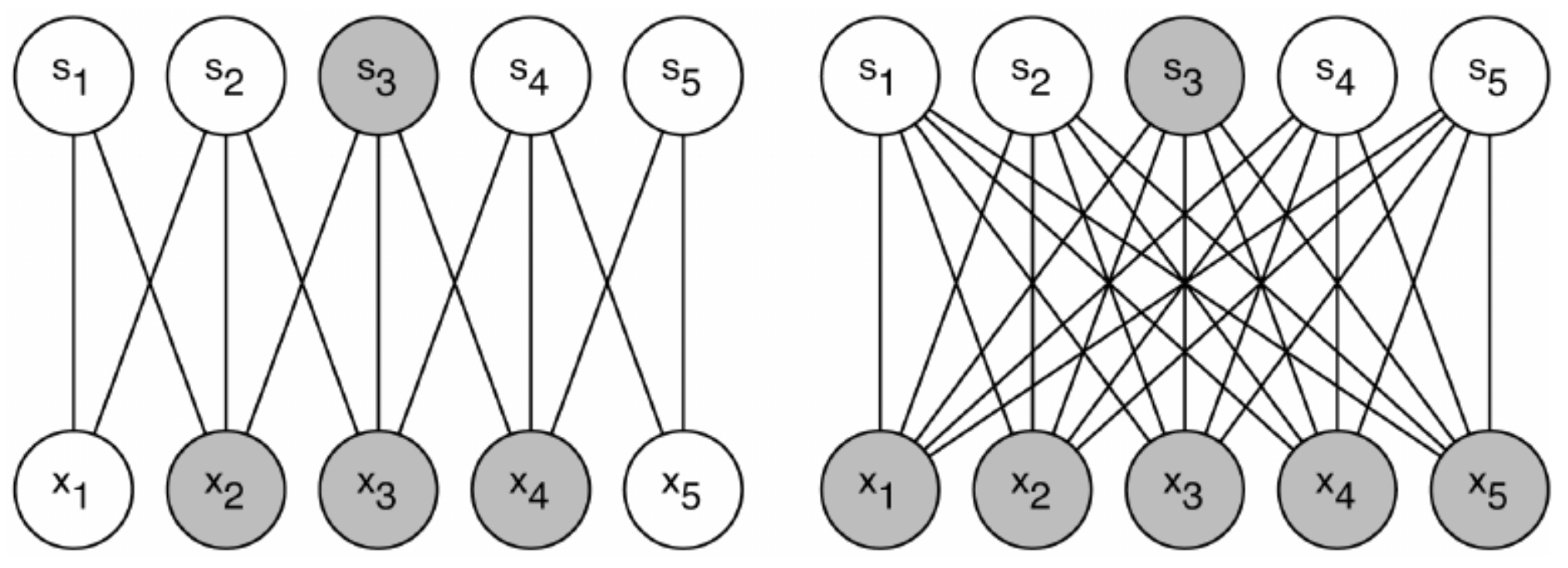
CNN의 이미지데이터는 벡터값으로 처리되는데, 필터를 이용한 Conv연산, Pooling 모두 행렬(Matrix) 연산을 합니다. 그래서 Sparse하게 연결 연산대상이 적으면 연산량이 줄어들거라 예상하지만, 우리의 예상과 달리 실제 Dense matrix연산 보다 Sparse Matrix연산이 더 큰 Computational resource를 사용합니다.
GoogLeNet 초기에는 CNN에 Sparse 한 CNN 연산을 사용하였습니다. 이 후, 연산을 병렬처리 하기위해 Dense Connection을 사용했고, Dense Matrix의 연산 기술이 발전했습니다. 그러나, Sparse Matrix연산은 그 만큼 발전하지 못했고, Dense Matrix 연산 보다 비효율적이게 됩니다. 따라서, 하이퍼파라미터를 조정하여 부담스러운 Computational resource를 해결하기 위해 Sparse connectivity를 사용하는 것이 정답이 아니였습니다.
하지만!!
구글의 Inception 모델은 이러한 문제와 고민의 결과가 되었습니다.
Inception-v1 (Better GoogLeNet)
구글이 어떻게 GoogLeNet을 얼마나 딥하게 구성했는지, 그리고 어떻게 해결했는지 보겠습니다.

GoogLeNet이 위 그림처럼 아주 딥한 신경망으로 구성되어 학습이 가능했던 것은 Inception Module 때문입니다.
Inception Module은 입력값에 대해, 4가지 종류의 Convolution, Pooling을 수행하고, 4개의 결과를 채널 방향으로 합칩니다. 이러한 Inception Module이 모델에 총 9개가 있습니다.

Inception Module에서 4가지 연산들은 다음과 같습니다.
1) 1x1 convolution
2) 1x1 convolution + 3x3 convolution
3) 1x1 convolution + 5x5 convolution,
4) 3x3 MaxPooling + 1x1 convolution
...그리고, 이 4개의 연산결과를 Channel-wise Concat(feature map을 쌓는 것)
Inception Module에서 Feature Map을 효과적으로 추출하기 위해 1x1, 3x3, 5x5 의 Convolution 연산을 각각 수행하며, 3x3 MaxPooling에서 입력과 출력 Matrix의 Height, Width를 같아야하므로 Pooling 연산에서 Padding을 추가해준다.
Feature Map을 추출하는 과정에서 최대한의 Spare 한 연결을 유지하고, Matrix 연산에서는 최대한 Dense하게 하고자 하였습니다. 그러나 이런 구조가 엄청난 Computational Resource를 사용하게됩니다.
이를 해결하기 위해 3x3, 5x5 Conv 연산 전에 그리고 3x3 MaxPooling 이후 1x1 Conv가 먼저 진행되는 겁니다.

1x1 convolution 가 추가되어 굳이 있어야하나 애매하게 보일 수 있습니다. 그러나 이 1x1 convolution은 Inception module에서 핵심 역할을 합니다. 1x1 Conv을 넣어 channel을 줄였다가, 다음의 3x3나 5x5 Conv에서 다시 확장하는데, 이렇하여 필요한 연산양을 감소시킵니다. 또한 1x1 Conv를 다음의 3x3 MaxPooling의 경우 Pooling연산의 결과 채널의 수가 이전의 입력과 동일하므로 이 역시 연산량을 줄여주기 위함입니다. 이렇게 sparse하게 각 연산을 거친 다음, dense한 output을 만들어내는데요, H와 W는 모두 동일하다는 것에 주의해야합니다. 즉 Concat연산을 channel에 적용한다고 보시면 될 것 같습니다.
1x1 Conv의 효과에 대한 자세한 설명은 다음과 같습니다.
(1) 채널의 수를 조절 기능
채널의 수를 조정한다는 의미는 , 채널 간의 Correlation을 연산한다 뜻입니다. 기존의 convolution 연산, 예를 들어 3x3의 필터로 연산 할 경우, 3x3 크기의 지역 정보와 함께 채널 간의 정보 또한 같이 고려하여 하나의 값으로 나타냅니다. 다르게 말하면, 하나의 커널이 2가지의 역할을 모두 수행해야 한다는 것이다.
만약, 1x1 convolution을 사용한다면, 1x1은 채널을 조절하는 역할을 하기 때문에, 최적화 과정에서 채널 간의 특징을 추출 할 것이고, 3x3은 이미지의 지역정보에만 집중하여 특징을 추출하려 할 것입니다. 필터 크기로 역할을 세분화 해준 것이다. 채널간의 관계정보는 1x1 convolution에 사용되는 파라미터들 끼리, 이미지의 지역 정보는 3x3 convolution에 사용되는 파라미터들 끼리 연결된다는 점에서 노드 간의 연결을 줄였다고 볼 수 있습니다.
(2) 채널 감소 => 파라미터 수 감소
1x1 convolution연산으로 이미지의 채널을 줄여준다면, 3x3과 5x5 convolution 레이어에서의 파라미터 개수를 절약 할 수 있다. 이 덕분에 망을 기존의 CNN 구조들 보다 더욱 깊게 만들고도 파라미터가 그리 크지 않다.
이 v1 모델에서 첫번째 계층을 Stem Layer라고 하는데 v3 모델까지 사용합니다. 이 첫번째 계층은 Convolution 연산을 하는데, 학습에 큰 영향을 주며 일반적인 CNN 모델과 같습니다. 이 모델의 마지막에는 Feature Map의 크기와 같은 필터크기로 Average Pooling을 수행한 후 fully connected layer를 지나 softmax 함수로 예측 결과물을 보여줍니다. 여기서 파라미터 수 를 결정하는 큰 요인 중 하나인 fully connected layer에서 적게 사용하면 파라미터 수를 더욱 절약할 수 있었습니다.
이렇게 파라미터에 대한 연산량을 개선한 v1 모델은 다음과 같습니다.

위의 모델에서 주목해야할 점은 모델 앞부분에서 Inception Module을 사용하지 않았고, 중간 중간 Softmax로 인한 Auxiliary Classifiers가 존재합니다.
우선 이 뉴럴네트워크 모델의 입력층 근처의 앞이 Inception이 없는 이유는 논문에서 이 앞부분에서 Inception의 효과가 나타나지 않았다고 하여 일반적인 CNN 구조로 연산을 시작합니다.
두번째를 보면 Softmax 로 Classifier 예측이 맨끝뿐만아닌 중간에 2번 있다는 점입니다. 자세히 그림을 살펴보면 중간단계에서 예측을 하는 부분있는데 이 부분을 Auxiliary Classifiers 라고 합니다. 신경망이 Deep하기 때문에 Gradient(for Error BackPropagation)가 모든 레이어로 잘 흘러가지 않을 수 있다고 판단하여, 신경망 중간에 예측결과를 출력하여 정규화 효과를 노린 것입니다. (Local response normalization)
이 논문에 주요 이슈가 Deep한 네트워크 구조로 인한 Vanishing Gradient Problem이며, 적절하게 BackPropagation이 적용되기 위한 방법이 연구된것입니다.
Auxiliary Classifiers 에서 계산된 error 값들은 0.3이라는 가중치와 곱해져, 최종 error 값에 더해집니다. 그리고, 실제 테스트에서는 Auxiliary Classifiers 부분을 사용하지 않았고 맨끝에만 Softmax를 사용하였습니다.
AlexNet과 비교하여 Alex에서는 전체 파라미터의 개수보다 10~12 분의 1 정도의 GoogLeNet Inception v1모델의 파리미터 개수가 됩니다.(GoogLeNet's Params 6.8M)
각 필터의 결과를 합쳐(Concat) 표현하는 것이 Inception Module이며, GoogLeNet처럼 아주 Deep한 신경마에서서도 1x1 Conv를 적극 함께 연산하여 연산량을 줄였습니다.
이러한 아이디어는 Network in Network에서도 등장합니다.
Network In Network, Min Lin, National University of Singapore, 2013
Inception-v2
Inception-v2 모델은 v1모델을 발전한 모델로 2015년에 발표한 논문에서 등장한 모델입니다.
ReThinking the Inception Architecture for Computer Vision, Christian Szergedy, Google Inc, 2015
**출처 & 참고**
https://kangbk0120.github.io/articles/2018-01/inception-googlenet-review
https://datascienceschool.net/view-notebook/8d34d65bcced42ef84996b5d56321ba9/
https://norman3.github.io/papers/docs/google_inception.html
https://arxiv.org/abs/1409.4842
https://arxiv.org/abs/1512.00567
https://arxiv.org/abs/1602.07261